
Afterword
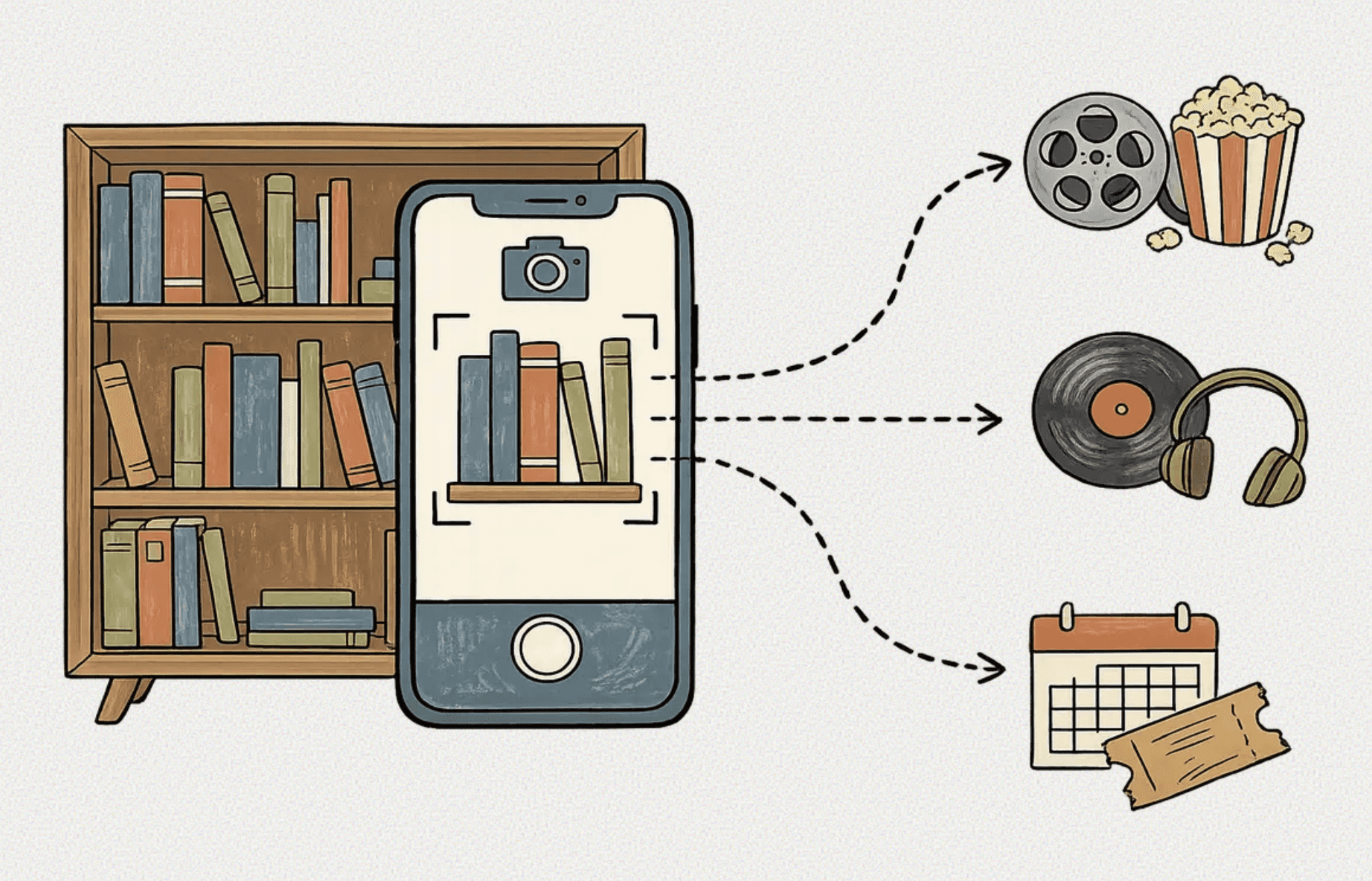
Afterword translates your physical bookshelf into a personalized digital taste profile, recommending movies, music, and podcasts based on the books you already own.

Afterword is Live
Afterword is a working prototype in active development. Try it out on your phone. Upload a photo of your bookshelf and see your taste mapped across books, films, music, and podcasts.
Reading the Room
Translating Taste & Designing for Trust
In a streaming-first world, the home bookshelf remains one of the last physical spaces where we actively put our taste on display. A bookshelf is rarely just a literal record of what someone has read. It is more often a deliberate, highly curated signal of what they want the world to know about them, offering a heightened level of insight into a person’s self-conception, taste, and identity.
Yet, our digital recommendation algorithms miss this rich, physical data completely, and most media recommendations remain locked in their respective medium silos. Your music taste doesn't talk to your favorite films, and neither talks to your bookshelf. Afterword was born from a specific challenge: How can we use frontier AI to extract this physical identity-signaling and map it into a cross-media digital profile?
It is a proof-of-concept application that bridges the physical and digital creative worlds. By allowing a user to snap a photo of their physical bookshelf, the application uses multimodal vision capabilities to extract the titles, analyze the underlying thematic "DNA" of the collection, and dynamically map those tastes to surface targeted recommendations across books, films, music, and podcasts.
However, building for this audience introduces a fascinating product tension: the intersection of analog curation and digital privacy. Individuals who meticulously maintain physical libraries are often highly protective of their data and naturally wary of scanning their personal spaces into an AI system. Afterword was designed not just to map cross-media tastes, but to solve for this exact trust deficit, proving that frontier AI can interact with personal data securely, transparently, and respectfully.
Guided Demo
Designing for the Bookish User
To bridge this trust gap, the visual identity of the application had to feel inherently safe and familiar. I utilized advanced image prompting to generate a UI that is aesthetically warm, cozy, and humanistic.
By employing a hand-drawn, tactile visual language, Afterword avoids the sterile, hyper-futuristic UI typical of many AI products. Every visual decision was calculated to ensure the product felt physical, empathetic, and welcoming, actively working to avoid alienating a traditionally analog audience.

To build this rapidly as a solo technologist, I utilized Cursor as my primary development environment. By leveraging Claude 4.6 Sonnet for LLM-assisted architecture, I was able to translate high-level system logic into a modern, responsive front-end integrated seamlessly with Anthropic's frontier vision model. This workflow directly demonstrates how creative professionals can leverage modern AI tooling to build bespoke, production-ready applications.
Frontend Framework: Next.js, React, TypeScript
Styling & UI: Tailwind CSS, AI-generated custom assets
AI / API: Anthropic API (Claude 4.6 Sonnet Vision)
Development Environment: Cursor (using Claude 4.6 Sonnet for LLM-assisted architecture and rapid prototyping)
Architecture Flow:
Image Capture: User securely uploads a high-resolution image of a bookshelf.
Vision Processing: Image is routed via API to Claude for visual extraction of spine text and visual clustering.
Thematic Analysis: The LLM synthesizes the extracted titles to identify underlying narrative themes, genres, and cultural affinities.
Cross-Domain Mapping: The system generates corresponding recommendations across distinct media formats (Books, Films, Music, and Podcasts).
JSON Structuring: Data is returned in a strictly formatted JSON object and parsed into the React front-end.
Latency Mitigation
Processing complex high-resolution images through a multimodal LLM introduces inherent latency. To mitigate this, I first built a typographic animation that communicates the work happening in the background. I am now in the process of integrating custom Rive animations into the loading state: an animation of a book opening as branches and leaves organically grow from its pages. This transforms the asynchronous API wait time from a friction point into a moment of visual delight. Instead of exposing the mechanical 'thought process' of the model, the animation reinforces the application's warm, humanistic aesthetic and serves as a visual metaphor for how our tastes naturally branch out across different mediums.
Iteration 1: Proof of Concept
The core challenge wasn't just extracting text; it was steering the model to return predictable, machine-readable data without hallucinating titles from blurry book spines. I applied strict guardrails directly within the system prompt, enforcing a rigid JSON schema and explicitly restricting prose or markdown. Coupled with custom regex stripping and a dedicated response normalization function in the codebase, this two-tiered approach successfully coerces and validates the output, ensuring the Next.js front-end receives flawless data structures every time.
Iteration 2: From Job Description to Analytical Framework
The first version of Afterword's recommendation prompt worked. It produced results that were technically non-generic and culturally adjacent. But adjacent isn't the same as insightful, and that matters when surface-level recommendations surround us in our digital life.
The original prompt gave the model a role without enough of a reasoning framework. Describing the AI as "a literary and cultural critic analyzing a photo" tells it what to be, not how to think. The result was recommendations that were statistically plausible, the most common associations between an author and related works, rather than genuinely earned.
Example of v1 recommendations:

Example of v2 recommendations:

MCP Integration
From Static Recommendations to Agentic Tool-Use
The original Afterword architecture had a fundamental limitation: its music recommendations were text. A reader who trusted the model's taste still had to go find the music themselves, breaking the experience at exactly the moment it should deepen.
The next phase addresses this directly. By integrating Anthropic's open-source Model Context Protocol, Afterword gives the LLM the ability to act, not just recommend.
Phase 1: Building a Standalone MCP Server
Rather than hardcoding a standard Spotify API call into the frontend, I built a dedicated MCP microservice in TypeScript. This separates concerns cleanly: the LLM decides what music fits the shelf; the MCP server handles the tool-use layer that fetches real, playable Spotify URLs.
Phase 2: Engineering an Evaluative Agent Loop
A basic implementation would treat the MCP server as a blind pipeline: the model requests a track, the server returns whatever Spotify surfaces first. The problem is that Spotify's search results can be difficult to get right on the first try: search for a specific recording and you'll often get a tribute band or a karaoke version before the original.
To solve this, I engineered an evaluative loop into the system prompt. The LLM doesn't just trigger the search tool; it analyzes the returned data, identifies whether the result is a cover or low-quality match, and if so, autonomously reformulates its query and retries before finalizing its response. The model is acting as an agent, applying judgment at each step rather than passing data through uncritically.
Phase 3: The Serverless Pivot
Deploying this architecture revealed a hard production constraint: Vercel's serverless functions cannot sustain the persistent connections that a standard MCP stdio transport requires. Rather than abandoning the agentic workflow, I refactored the server, wrapping the logic in Express.js, migrating to a Server-Sent Events transport, and deploying the standalone repository to Render.
The result is a distributed architecture: Afterword's Next.js frontend on Vercel, the MCP server running persistently on Render, communicating over HTTP.
The music recommendations Afterword now surfaces aren't suggestions. They're live links — one tap from the music itself.
Future Plans
Expanding the Agentic Layer
The Spotify MCP integration proved the architecture. The next phase extends the same agentic tool-use model across the full recommendation stack.
Podcast MCP Server
A dedicated MCP server will connect the LLM to podcast directory APIs, enabling Afterword to surface playable episode links rather than show titles — routing the reader directly to a specific episode whose subject or guest reflects the thematic DNA of their shelf, not just a podcast they might generally enjoy.
Local Events MCP Server
The most contextually ambitious integration: a location-aware MCP server that connects to live events APIs to surface readings, screenings, gallery openings, and performances happening near the user.
Both integrations will require corresponding updates to the main agent's system prompt, extending the evaluative loop and reasoning framework developed in Iteration 2 to govern how the model selects and validates results across each new tool.
The longer arc of this work is straightforward: every recommendation Afterword makes should be one tap from the thing itself.
Future Application
While Afterword is a consumer-facing prototype, the underlying API routing architecture solves a much bigger problem for cultural institutions and media conglomerates. By proving that multimodal LLMs can successfully act as translation layers between physical artifacts and digital recommendations, this architecture can be scaled for:
Museums & Galleries: Allowing visitors to scan a piece of physical art and instantly receive a personalized audio tour based on their specific demographic or demonstrated affinities.
Publishers & Media Conglomerates: Building tools that map a user's viewing history on a streaming platform to specifically target backlist publishing IP, maximizing cross-platform revenue.